在當今數據爆炸的時代,如何高效、可靠地處理海量數據,成為了各行各業(yè)面臨的共同挑戰(zhàn)。Hadoop,作為大數據處理領域的奠基性框架,自誕生以來便為大規(guī)模數據處理提供了革命性的解決方案。它不僅僅是一個單一的工具,更是一個由多個核心組件構成的生態(tài)系統,其核心思想——分布式并行計算,已成為現代大數據處理的基石。
一、Hadoop的核心設計思想:分而治之
Hadoop的靈感來源于谷歌發(fā)表的MapReduce和Google File System(GFS)論文。其核心設計理念可以概括為“分而治之”:
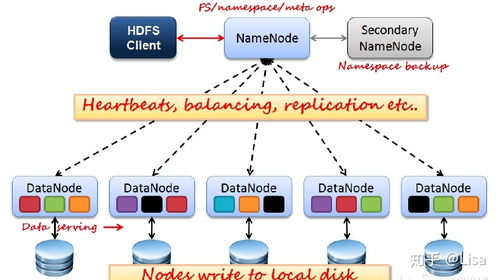
- 分布式存儲(HDFS):它將一個超大的文件(如TB、PB級別)自動切分成多個數據塊(默認128MB),并將這些數據塊分散存儲在一個由成百上千臺普通商用服務器組成的集群中。這樣,存儲的負載和風險就被分散了,即使部分服務器出現故障,數據也不會丟失,因為每個數據塊都有多個副本存儲在不同的服務器上。
- 分布式計算(MapReduce):“計算向數據靠攏”。當需要對海量數據進行處理時(如統計、排序、分析),Hadoop會將計算任務(一個作業(yè))分解成大量小的計算單元(Map任務和Reduce任務),然后將這些小的任務調度到存儲著相關數據塊的服務器上去執(zhí)行。這極大地減少了數據在網絡中的傳輸,提高了處理效率。
二、Hadoop的核心組件
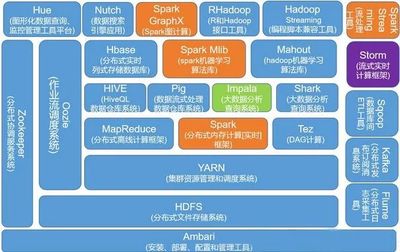
一個典型的Hadoop生態(tài)系統主要包含以下核心組件:
- HDFS(Hadoop Distributed File System):分布式文件系統,負責數據的存儲。它是Hadoop的“硬盤”,具有高容錯性、高吞吐量的特點。
- MapReduce:分布式計算框架,負責數據的計算。它是一種編程模型,用戶只需編寫Map和Reduce兩個函數,即可將復雜的并行計算任務交由框架自動完成。
- YARN(Yet Another Resource Negotiator):資源管理和作業(yè)調度系統。在Hadoop 2.0之后引入,它將資源管理和作業(yè)調度/監(jiān)控的功能分離,使得Hadoop可以運行除MapReduce之外的其他計算框架(如Spark、Flink),大大提升了集群的利用率和靈活性。
三、數據處理的基本流程(以MapReduce為例)
假設我們有一個巨大的文本文件,需要統計其中每個單詞出現的次數,Hadoop的處理流程如下:
- 輸入與分片:HDFS中的大文件被自動切分為多個數據分片。每個分片(如128MB)會啟動一個Map任務。
- Map階段:每個Map任務讀取分配給它的數據分片,逐行處理。對于每一行文本,Map函數會將其拆分成單詞,并為每個單詞輸出一個中間鍵值對,例如
<單詞, 1>。這個過程在所有Map節(jié)點上并行執(zhí)行。 - Shuffle與排序:這是框架自動完成的“魔法”步驟。系統會將所有Map任務輸出的、具有相同鍵(即相同單詞)的中間結果收集起來,通過網絡傳輸到同一個Reduce任務節(jié)點,并按鍵進行排序。
- Reduce階段:每個Reduce任務接收一組按鍵分組好的數據(如所有“Hadoop”單詞的計數列表
[1,1,1,...])。Reduce函數對這組值進行合并計算(如求和),并輸出最終結果,例如<Hadoop, 1500>。 - 輸出:所有Reduce任務的輸出最終被寫入HDFS,形成最終結果文件。
四、Hadoop的優(yōu)勢與局限
優(yōu)勢:
高可靠性:數據多副本存儲,計算任務自動重試,硬件故障對應用透明。
高擴展性:可通過線性增加廉價服務器來擴展存儲和計算能力。
成本低廉:建立在普通商用服務器集群上,相比大型機和小型機,成本極低。
成熟的生態(tài):擁有豐富的周邊工具(如Hive用于SQL查詢,HBase用于實時數據庫,Sqoop用于數據導入導出等)。
局限:
MapReduce編程模型相對復雜:對于復雜的數據處理邏輯,編寫MapReduce程序不夠直觀和高效。
實時性差:MapReduce作業(yè)的啟動開銷大,且基于磁盤的Shuffle過程較慢,不適合實時或迭代式計算(這正是后來Spark等框架著力解決的問題)。
* 資源管理在早期版本中不夠靈活:YARN的引入已大大改善此問題。
###
盡管如今出現了許多性能更優(yōu)、使用更便捷的新一代大數據處理框架(如Apache Spark),但Hadoop所奠定的分布式思想、HDFS提供的可靠存儲方案以及YARN構建的資源管理層,依然是整個大數據技術棧不可或缺的底層支柱。理解Hadoop,是理解大數據處理技術演進脈絡的關鍵第一步。對于希望進入大數據領域的學習者而言,掌握Hadoop的基本原理,就如同學習編程需要理解計算機基礎一樣重要。